NVIDIA presenta SpatialClaw, el sistema sin entrenamiento que revoluciona
SpatialClaw transforma la forma en que los modelos de visión e idioma comprenden el espacio tridimensional, utilizando código como interfaz de acción en lugar de entrenamiento adicional.
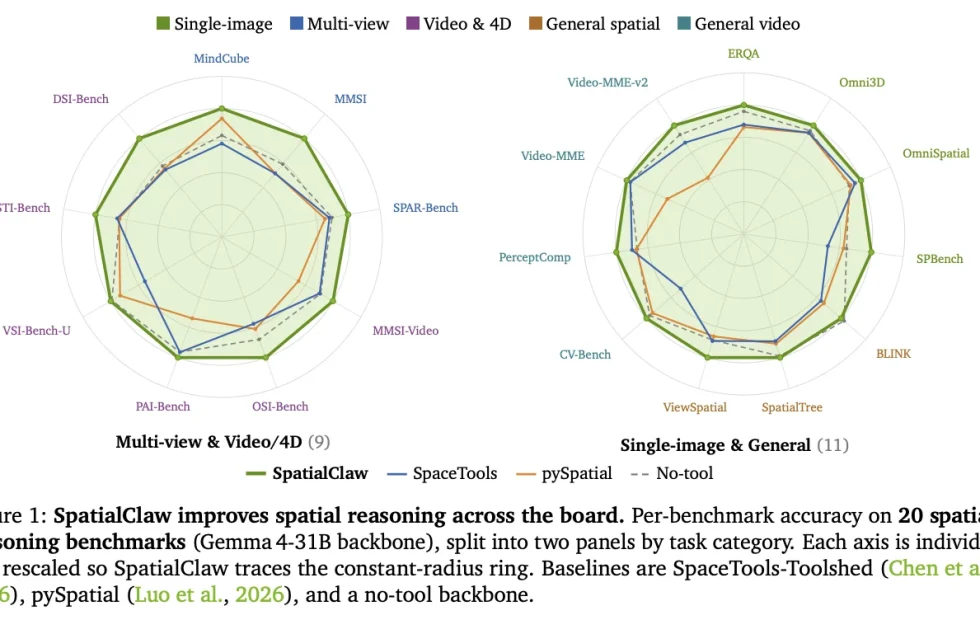
NVIDIA Research ha dado un paso significativo en la evolución del razonamiento espacial con el lanzamiento de SpatialClaw, un sistema que redefine la interacción de los modelos de visión-lenguaje (VLM) con entornos tridimensionales. En lugar de depender del entrenamiento adicional, la propuesta se basa en una interfaz de código que permite al agente ejecutar herramientas de percepción para entender la profundidad, posición y movimiento de los objetos en 3D, logrando una precisión promedio superior al 59% en distintas pruebas y superando a sus predecesores en múltiples escenarios.
SpatialClaw representa un cambio conceptual dentro de la investigación en comprensión visual avanzada. Frente a los modelos tradicionales que requieren enormes volúmenes de datos para perfeccionar su entrenamiento, NVIDIA propone una arquitectura que no necesita reentrenarse. El secreto está en la interfaz que conecta el modelo con las herramientas de percepción, un componente clave que, según la propia compañía, limitaba el rendimiento de los agentes anteriores.
SpatialClaw NVIDIA: Un agente que utiliza código para razonar en el espacio
La característica más innovadora de SpatialClaw es que trata el código como medio de acción. En lugar de depender exclusivamente de instrucciones en lenguaje natural, el sistema genera y ejecuta fragmentos de código Python dentro de un núcleo persistente. Ese entorno permite establecer un diálogo continuo entre la percepción visual y la lógica de razonamiento.
El funcionamiento se basa en un bucle de cinco etapas: planificación, generación de código, ejecución, ensamblado de retroalimentación y entrega de respuesta. Cada bloque de código se revisa antes de ejecutarse gracias a un verificador sintáctico que evita operaciones inseguras. Este enfoque combina la flexibilidad de los lenguajes de programación con la capacidad de análisis de los modelos más potentes de la actualidad.
Para profundizar el contexto, también se puede leer: NVIDIA presenta Dynamo Snapshot para acelerar la inferencia en Kubernetes.
Para profundizar el contexto, también se puede leer: Perplexity presenta Brain: Un sistema de memoria que mejora la eficiencia.
Componentes y arquitectura técnica
El núcleo de SpatialClaw se construye sobre un kernel de Python que mantiene el estado a lo largo de la ejecución. Dentro de ese entorno se cargan las imágenes de entrada, los metadatos de cada cuadro y un conjunto de herramientas de percepción denominadas primitives. Estas herramientas son funciones Python que devuelven mapas de profundidad, máscaras de segmentación, geometría de cámara y trayectorias de movimiento, todas representadas como variables ordinarias.
El sistema cuenta con seis puntos de acceso públicos: InputImages, que almacena los cuadros de entrada; Metadata, con información de tasa de cuadros y duración; tools, que agrupa las utilidades de percepción; el método show(), para insertar imágenes en el contexto de la próxima ejecución; vlm, para enviar consultas al modelo de lenguaje-visual; y ReturnAnswer(), que finaliza el ciclo de razonamiento.
Dos de las herramientas más relevantes son tools.Reconstruct, que incorpora el modelo Depth Anything 3 para calcular mapas de profundidad y parámetros intrínsecos y extrínsecos de la cámara, y tools.SAM3, que emplea SAM 3 para generar máscaras de imagen o video a partir de texto o puntos de referencia. Además, se suman utilidades adicionales como tools.Geometry, tools.Mask, tools.Time, tools.Graph y tools.Draw.
Resultados y comparación de desempeño
El equipo de NVIDIA probó SpatialClaw en 20 bancos de prueba agrupados en cinco categorías que abarcan desde imágenes únicas hasta comprensión de video y entornos 4D. En todos los casos, el sistema superó al modelo base sin herramientas, con mejoras consistentes en las seis arquitecturas de referencia, que van desde los 26 mil millones hasta los 397 mil millones de parámetros. En promedio, alcanzó un 59,9% de precisión, superando al anterior agente espacial SpaceTools por más de 11 puntos porcentuales.
Las pruebas más exigentes se realizaron sobre la familia Gemma4, donde SpatialClaw alcanzó incrementos notables en tareas dinámicas. En la evaluación DSI-Bench obtuvo una mejora de 17,6 puntos, mientras que en MindCube el incremento fue de 15,3. Estas mediciones reflejan el potencial del sistema para resolver problemas que requieren cálculos geométricos encadenados entre múltiples cuadros o perspectivas.
Por qué esta noticia es relevante
La importancia de SpatialClaw radica en su enfoque sin entrenamiento, una metodología que puede transformar la manera en que se amplían los modelos existentes. Permite a equipos de investigación y empresas mejorar la capacidad de razonamiento espacial sin necesidad de recopilar nuevos datos ni realizar costosos procesos de ajuste fino. Esta posibilidad abre el camino hacia agentes más flexibles que puedan adaptarse rápidamente a tareas visuales o industriales sin depender de recursos adicionales.
Desde el punto de vista del desarrollo de software y la automatización, el hecho de considerar el código como interfaz de acción plantea un modelo híbrido: el razonamiento conceptual de los modelos de lenguaje se combina con la precisión estructurada de la ejecución programática. Esto podría influir en ámbitos como el diseño de robots, la simulación 3D, el análisis de imágenes médicas o el control de flujos logísticos en tiempo real.
Cómo encaja dentro de la evolución del sector
En los últimos años, la investigación en visión-lenguaje ha avanzado de manera vertiginosa, pero aún presenta dificultades para comprender las relaciones espaciales. Modelos anteriores lograban identificar objetos, sin embargo, fallaban al estimar posiciones relativas o distancias. SpatialClaw aborda precisamente esa debilidad. Al integrar un enfoque de composición de código, el agente puede calcular distancias mediante estructuras KD-tree, determinar direcciones con productos punto o combinar múltiples herramientas en un mismo flujo lógico.
En el ecosistema actual, donde la demanda de inteligencia visual aplicada crece tanto en vehículos autónomos como en sistemas de realidad aumentada, esta solución se presenta como un marco ideal para tareas que requieren razonamiento geométrico paso a paso. Además, su compatibilidad con infraestructuras como LangGraph y kernels Jupyter persistentes facilita su integración en flujos de trabajo de investigación y desarrollo.
Otro aspecto destacable es su independencia de una categoría específica. El mismo conjunto de herramientas, parámetros e indicaciones se emplea en los veinte bancos de prueba, lo que demuestra la solidez de su diseño. Para las organizaciones, esto implica la posibilidad de reutilizar el mismo agente en contextos heterogéneos, desde inspección visual hasta modelado de entornos complejos.
Aplicaciones prácticas y perspectivas futuras
La adopción de SpatialClaw podría acelerar la implementación de soluciones industriales que requieren comprensión espacial avanzada sin depender de grandes inversiones en entrenamiento. Por ejemplo, en fábricas automatizadas podría emplearse para monitorear la posición de componentes en tiempo real, o en logística para analizar la ocupación de contenedores. En el ámbito médico, sus algoritmos podrían asistir en el análisis tridimensional de estudios por imágenes, complementando diagnósticos con métricas de distancia o movimiento.
En el entorno académico, las universidades y laboratorios podrían aprovechar su estructura modular para probar nuevas combinaciones de herramientas de percepción. Al no requerir ajuste fino, el sistema facilita la experimentación rápida, reduciendo el tiempo entre la concepción de una idea y su validación empírica.
Asimismo, SpatialClaw introduce una filosofía de razonamiento programable que podría inspirar futuras generaciones de agentes. En lugar de delegar todas las decisiones a un modelo central, promueve una interacción transparente donde cada paso puede analizarse y modificarse. Esto mejora la trazabilidad y la posibilidad de corregir errores sin alterar la base del modelo.
Qué puede ocurrir a partir de ahora
El lanzamiento de SpatialClaw probablemente marcará un punto de inflexión en la forma en que se diseñan los agentes visuales. Es previsible que otros laboratorios adopten enfoques similares, priorizando estructuras donde la lógica de acción se exprese mediante código y no únicamente por inferencia estadística. Esta tendencia podría derivar en herramientas más interpretables y seguras, especialmente en contextos donde la verificabilidad es esencial, como la conducción autónoma o la robótica industrial.
Otro efecto esperado es la expansión de ecosistemas abiertos que integren estos agentes dentro de plataformas colaborativas. NVIDIA ya aloja el proyecto en un repositorio oficial que combina tecnologías como FastAPI, vLLM y flujos LangGraph. Gracias a esta arquitectura, cualquier investigador o desarrollador puede ejecutar un entorno completo en una sola máquina y experimentar con sus propias pruebas.
A medida que los modelos de percepción y lenguaje continúen creciendo en capacidad, soluciones como SpatialClaw ofrecerán una vía para aprovechar ese poder sin multiplicar los costos de entrenamiento. Su concepción modular y su compatibilidad con diversas arquitecturas la posicionan como una herramienta estratégica para el futuro de la visión computacional aplicada.
En definitiva, el aporte de NVIDIA no solo reside en los resultados obtenidos, sino en la idea de fondo: usar el código mismo como instrumento de razonamiento. Este paradigma podría convertirse en una referencia para toda una nueva generación de sistemas capaces de entender el espacio con precisión y adaptabilidad sin precedentes.
Preguntas frecuentes
¿Qué es exactamente SpatialClaw?
Es un marco de razonamiento espacial desarrollado por NVIDIA que usa código Python como interfaz de acción para analizar relaciones tridimensionales.
¿Por qué es relevante el enfoque sin entrenamiento?
Porque permite mejorar modelos existentes sin recopilar nuevos datos ni realizar ajustes costosos, reduciendo tiempo y recursos.
¿Qué resultados obtuvo en las pruebas?
Superó en más de 11 puntos a su predecesor y alcanzó una precisión promedio de 59,9% en 20 bancos de prueba.
Más noticias de este autor



Seguimiento del tema
Esta cobertura puede ampliarse con nuevas fuentes, consultas de búsqueda y artículos relacionados dentro del mismo eje editorial.