Creación de un Pipeline de Datos de Código con NVIDIA Nemotron y Pandas
Exploramos cómo construir un pipeline de datos de código utilizando el conjunto de datos Nemotron-Pretraining-Code-v3 de NVIDIA, empleando transmisión de datos y análisis con Pandas.
Esta noticia se relaciona con pipeline de datos de código y puede impactar en tendencias de Inteligencia Artificial, posicionamiento, automatización y toma de decisiones digitales.
La inteligencia artificial dejó de ser una promesa lejana y ya forma parte de procesos concretos en marketing, contenidos, atención al cliente y productividad.
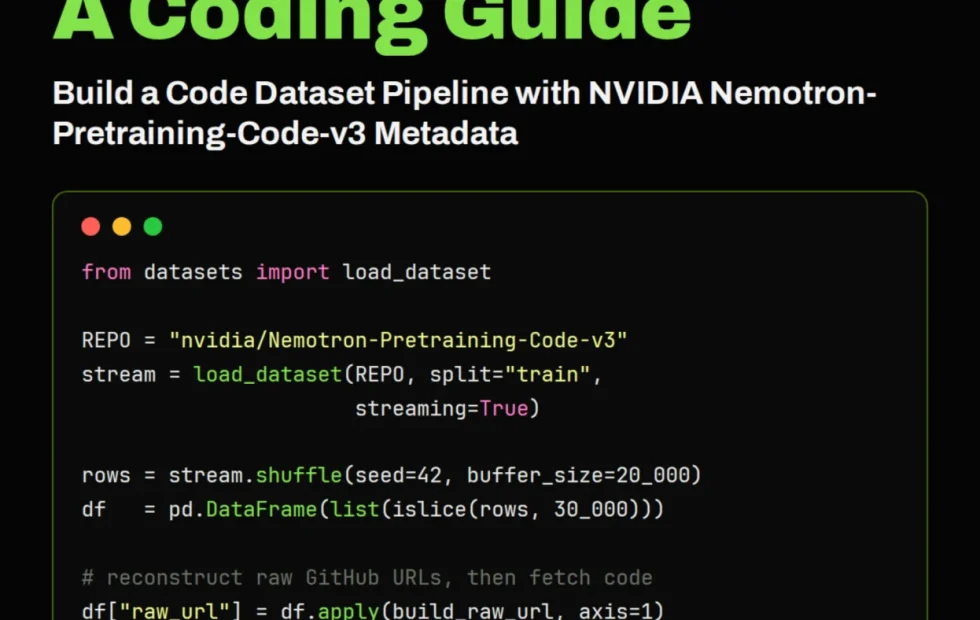
El avance en la investigación de preentrenamiento de código ha llevado a la utilización de conjuntos de datos masivos como Nemotron-Pretraining-Code-v3 de NVIDIA. En este artículo, exploramos cómo construir un pipeline de datos eficiente empleando técnicas de transmisión de datos y herramientas como Pandas y tiktoken para analizar y manipular metadatos a gran escala.
En el ámbito de la investigación en inteligencia artificial, el preentrenamiento de modelos con grandes volúmenes de datos de código se ha convertido en una práctica común. NVIDIA ha desarrollado el conjunto de datos Nemotron-Pretraining-Code-v3, que sirve como un índice de metadatos a gran escala para tales investigaciones. Este artículo detalla cómo construir un pipeline de datos de código utilizando este conjunto de datos, centrándonos en la transmisión de datos y el uso de herramientas como Pandas y tiktoken.
Exploración del conjunto de datos Nemotron
El conjunto de datos Nemotron-Pretraining-Code-v3 de NVIDIA es un recurso valioso para investigadores interesados en el preentrenamiento de modelos de código. En lugar de descargar el voluminoso conjunto de datos completo, optamos por transmitirlo, lo que nos permite manejar los datos de manera más eficiente. La transmisión de datos nos permite inspeccionar el esquema del conjunto de datos y construir una muestra manejable para análisis detallados.
Análisis de lenguajes y extensiones de archivo
Uno de los primeros pasos en nuestro análisis fue estudiar los lenguajes de programación y las extensiones de archivo presentes en el conjunto de datos. Esto nos permitió entender mejor la estructura del índice de metadatos y evaluar la frecuencia de los repositorios y la profundidad de los directorios. Utilizando Pandas, construimos un DataFrame que facilitó el análisis exploratorio de estas características.
Visualización de patrones en los metadatos
Para interpretar mejor los patrones encontrados en los metadatos, utilizamos gráficos que representan los lenguajes más comunes, las extensiones de archivo más frecuentes, la profundidad de anidación de directorios y la frecuencia de los repositorios. Estas visualizaciones nos proporcionaron una perspectiva clara de las estructuras dominantes dentro del índice de metadatos.
Reconstrucción de URLs de GitHub y obtención de archivos fuente
Un paso crucial en nuestro proceso fue la reconstrucción de URLs de GitHub a partir de los metadatos, lo que nos permitió intentar obtener archivos fuente reales. Esto implicó manejar casos de archivos faltantes, eliminados o privados, así como aquellos que excedían el tamaño permitido. Pudimos previsualizar algunos archivos obtenidos con éxito para verificar la conexión entre los metadatos y el contenido de código real.
Filtrado y estimación de escala de tokens
Finalmente, filtramos el índice de muestra para archivos de Python y estimamos los conteos de tokens de los archivos obtenidos exitosamente. Esta estimación de tokens nos proporcionó una idea de la escala del conjunto de datos completo, lo que es esencial para planificar futuros experimentos y análisis.
Por qué esta noticia es relevante
La capacidad de manejar y analizar grandes volúmenes de datos de código es crucial en la investigación de inteligencia artificial, especialmente para el desarrollo de modelos de preentrenamiento. Este enfoque no solo optimiza el uso de recursos, sino que también facilita el acceso a datos actualizados y relevantes para investigadores en todo el mundo.
Cómo encaja dentro de la evolución del sector
La transmisión de datos y el análisis de metadatos a gran escala son tendencias emergentes en el campo de la ciencia de datos y la inteligencia artificial. La capacidad de trabajar con conjuntos de datos masivos sin necesidad de descargarlos en su totalidad representa un avance significativo en la eficiencia del procesamiento de datos.
Qué puede ocurrir a partir de ahora
Con la continua evolución de las herramientas de análisis de datos y la creciente disponibilidad de conjuntos de datos masivos, es probable que veamos un aumento en la adopción de técnicas de transmisión de datos en diversas áreas de investigación. Esto podría llevar a desarrollos más rápidos y eficientes en modelos de inteligencia artificial y aprendizaje automático.
Impacto específico para usuarios y empresas
Una cobertura responsable sobre inteligencia artificial debería diferenciar hechos confirmados, escenarios posibles, riesgos y criterios de uso antes de recomendar adopción.
Casos de uso que empiezan a aparecer
La lectura útil aparece cuando el tema se conecta con una aplicación concreta y no con una promesa genérica de automatización.
Qué desafíos siguen abiertos
El valor de esta tendencia dependerá menos del entusiasmo inicial y más de su capacidad para resolver necesidades concretas con seguridad, utilidad y control humano.
Impacto específico de pipeline de datos de código
La relevancia de esta novedad no se mide por mencionar inteligencia artificial, sino por explicar qué cambia en el caso concreto: quién puede usarlo, qué problema intenta resolver y qué límites conviene considerar antes de convertirlo en una recomendación.
En torno a Creación de un Pipeline de Datos de Código con NVIDIA Nemotron y Pandas, el análisis debe concentrarse en la experiencia real de usuarios, equipos o empresas alcanzadas por el tema. Esa mirada evita transformar cualquier noticia de IA en una lectura genérica sobre automatización.
Aplicaciones concretas y puntos que requieren seguimiento
Para evaluar el alcance de pipeline de datos de código, conviene observar si existen usos prácticos, ejemplos verificables, documentación disponible o señales de adopción. Si la información todavía es limitada, la cobertura debe separar hechos confirmados de interpretaciones posibles.
- Identificar qué necesidad específica intenta resolver.
- Revisar si el beneficio es para usuarios finales, empresas o equipos técnicos.
- Observar riesgos de privacidad, dependencia o calidad de resultado cuando correspondan.
- Actualizar la nota si aparecen casos reales, fuentes oficiales o nuevos datos.
Qué puede cambiar para el lector
El valor editorial aparece cuando el lector entiende si esta tendencia puede modificar una decisión concreta: adoptar una herramienta, revisar una estrategia, cambiar un flujo de trabajo o simplemente seguir el tema con más contexto. La cobertura debe ayudar a decidir, no solo sumar volumen de texto.
Preguntas frecuentes
¿Qué es el conjunto de datos Nemotron-Pretraining-Code-v3?
Es un índice de metadatos a gran escala desarrollado por NVIDIA para la investigación de preentrenamiento de código.
¿Por qué es importante la transmisión de datos?
Permite manejar grandes volúmenes de datos sin necesidad de descargarlos completamente, optimizando el uso de recursos y tiempo.
¿Cómo se utilizan Pandas y tiktoken en este proceso?
Pandas se utiliza para el análisis y manipulación de datos, mientras que tiktoken ayuda en la estimación de conteos de tokens en los archivos de código obtenidos.
Más noticias de este autor


Seguimiento del tema
Esta cobertura puede ampliarse con nuevas fuentes, consultas de búsqueda y artículos relacionados dentro del mismo eje editorial.