Liquid AI lanza LFM2.5-230M, su modelo más liviano optimizado para dispositivos
La compañía presentó LFM2.5-230M, un modelo de 230 millones de parámetros diseñado para ejecutar tareas de agentes y extracción de datos directamente en dispositivos como teléfonos y robots, superando a modelos de mayor tamaño en instrucciones y eficiencia.
Liquid AI dio a conocer su nuevo modelo LFM2.5-230M, una versión ultracompacta de su serie LFM2 pensada para correr en hardware local sin depender de la nube. Con apenas 230 millones de parámetros, este desarrollo se orienta a la ejecución de tareas automatizadas, control de robots y procesamiento de datos en entornos de baja latencia, marcando un paso importante hacia la inteligencia artificial verdaderamente embebida.
La presentación de LFM2.5-230M sitúa a Liquid AI en una posición destacada dentro del segmento de la inteligencia artificial optimizada para dispositivos. Con un tamaño de solo 230 millones de parámetros, este modelo busca ofrecer capacidades de razonamiento práctico, extracción de información y uso de herramientas directamente en equipos como smartphones, placas de desarrollo o robots autónomos.
Según Fuente original, la información se basa en Liquid AI Ships LFM2.5-230M with llama.cpp, MLX, vLLM, SGLang, and ONNX Support for On-Device Inference.
Un modelo reducido con grandes ambiciones técnicas
A diferencia de los grandes modelos de lenguaje que requieren servidores y GPUs de alto rendimiento, LFM2.5-230M se diseñó desde el inicio para ejecutarse localmente. De acuerdo con la publicación oficial en MarkTechPost, el modelo alcanza velocidades de 213 tokens por segundo en un Galaxy S25 Ultra y 42 en una Raspberry Pi 5, resultados considerables para un sistema que no depende de conexión externa.
El modelo está construido sobre la arquitectura LFM2 y cuenta con catorce capas internas: ocho bloques convolucionales de tipo LIV doblemente compuerta y seis bloques de atención de consulta agrupada (GQA). Esta estructura híbrida prioriza la inferencia en CPU, buscando un equilibrio entre rapidez y consumo de energía.
Características técnicas y compatibilidad
Entre sus especificaciones, LFM2.5-230M posee una longitud de contexto de 32.768 tokens y un vocabulario de 65.536 términos. Su conocimiento llega hasta mediados de 2024 y ofrece soporte multilingüe para diez idiomas, entre ellos inglés, chino, árabe y japonés.
Liquid AI publicó dos puntos de control: LFM2.5-230M-Base, orientado al afinado posterior, y LFM2.5-230M-Instruction, ya ajustado para tareas generales con instrucciones. Ambos se distribuyen con licencia abierta lfm1.0 y se encuentran disponibles en Hugging Face, lo que facilita la adaptación por parte de desarrolladores y empresas.
Un entrenamiento intensivo con 19 billones de tokens
El modelo fue preentrenado con más de 19 billones de tokens, incluyendo una fase de extensión de contexto que refuerza su comprensión en secuencias largas. Luego, el proceso de postentrenamiento se divide en tres etapas: ajuste supervisado con destilación desde el modelo mayor LFM2.5-350M, optimización de preferencias directa (DPO) y aprendizaje por refuerzo multidominio. Esta combinación permite que el modelo mantenga flexibilidad y precisión en escenarios diversos.
La destilación se revela como la clave del rendimiento: al heredar comportamientos del modelo más grande, el LFM2.5-230M logra competir eficazmente con sistemas de mayor tamaño en tareas específicas, sin perder su carácter compacto.
Comparativa frente a modelos de mayor tamaño
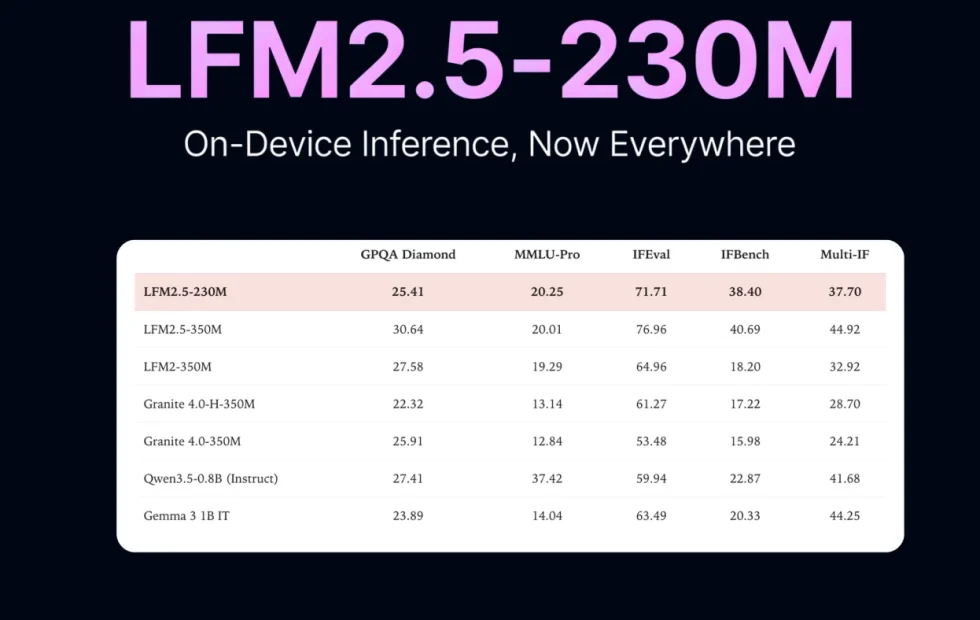
Liquid AI evaluó su modelo en diez métricas diferentes que abarcan conocimiento, seguimiento de instrucciones, extracción de datos y uso de herramientas. En pruebas como IFEval, obtuvo una puntuación de 71,71, superando a Qwen3.5-0.8B (59,94) y Gemma 3 1B IT (63,49). En IFBench alcanzó 38,40 y en CaseReportBench, dedicado a extracción clínica, logró 22,51 puntos.
Estos resultados confirman que LFM2.5-230M sobresale en obediencia a instrucciones y manejo de datos estructurados, aunque presenta limitaciones en conocimiento general y tareas que exigen razonamiento profundo. En el test MMLU-Pro obtuvo 20,25 puntos, detrás de los 37,42 de Qwen3.5-0.8B, y en τ²-Bench Telecom registró solo 5,26, mostrando que aún hay margen de mejora en entornos de herramientas complejas.
Aplicaciones en robótica y automatización
Una de las demostraciones más llamativas fue su ejecución en un robot humanoide Unitree G1, equipado con un módulo NVIDIA Jetson Orin. Allí actuó como capa de selección de habilidades, traduciendo instrucciones en lenguaje natural a secuencias de llamadas de herramientas dentro del marco SONIC de NVIDIA. Este enfoque permite que el robot interprete órdenes humanas y las convierta en acciones concretas en tiempo real, sin depender de conexión a servidores.
El modelo incorpora una estructura de llamadas a funciones basada en JSON, permitiendo definir herramientas en el prompt del sistema. Luego genera una invocación de función con sintaxis tipo Python, ejecuta el resultado y produce una respuesta en texto natural. Los desarrolladores pueden optar por representaciones forzadas en formato JSON, facilitando la integración con entornos de automatización y control.
Compatibilidad y recomendaciones de uso
LFM2.5-230M funciona con versiones de Transformers desde la 5.0.0. Los parámetros sugeridos para generación incluyen temperatura 0.1, top_k 50 y penalización de repetición 1.05, con la opción do_sample=True activada. Además, Liquid AI compartió recetas de entrenamiento y ajuste fino (SFT, DPO y GRPO con LoRA) disponibles en entornos Colab mediante Unsloth y TRL, lo que simplifica el trabajo de investigadores y startups que busquen personalizar el modelo.
Un paso hacia la IA embarcada y descentralizada
El lanzamiento de LFM2.5-230M se enmarca en una tendencia más amplia que busca trasladar parte del procesamiento de inteligencia artificial del servidor a los dispositivos finales. Este enfoque reduce la latencia, mejora la privacidad y abre oportunidades para aplicaciones en robótica, IoT, salud, domótica y automóviles inteligentes. La capacidad de operar desconectado ganó relevancia en entornos donde la conectividad no siempre está garantizada.
Para América Latina, estas innovaciones suponen una puerta de entrada a soluciones más accesibles: empresas locales podrían desarrollar asistentes, bots industriales o sistemas de soporte operativo sin depender de infraestructura en la nube, reduciendo costos y complejidad técnica.
Repercusiones en el desarrollo de modelos abiertos
La decisión de publicar pesos abiertos en Hugging Face refuerza el compromiso de Liquid AI con la investigación colaborativa. Este modelo se suma a la corriente de proyectos que buscan reproducibilidad y transparencia, en contraste con la tendencia de algunos competidores de mantener arquitecturas cerradas. Su licencia abierta también favorece la innovación comunitaria, permitiendo que desarrolladores independientes aporten mejoras o lo integren en nuevos productos.
Influencias y perspectivas futuras
El futuro de la línea LFM podría orientarse hacia una mayor optimización energética y especialización por dominios. Al integrarse con frameworks como llama.cpp, vLLM o ONNX, LFM2.5-230M demuestra compatibilidad con ecosistemas de inferencia eficientes, facilitando la portabilidad entre plataformas. Esta interoperabilidad será crucial para ecosistemas móviles y de robótica ligera donde cada milisegundo cuenta.
Impacto del lanzamiento en la visibilidad SEO y la competencia tecnológica
El anuncio de LFM2.5-230M también incide en la estrategia digital de las empresas de inteligencia artificial. Los modelos capaces de operar localmente generan interés de búsqueda asociado a términos como “IA en el dispositivo” o “modelo liviano”. Para sitios especializados en IA y SEO, cubrir estos lanzamientos con lenguaje técnico claro y comparaciones de rendimiento resulta clave para captar tráfico orgánico especializado. Al mismo tiempo, las compañías que adopten sistemas basados en inferencia local podrán diferenciar su propuesta en términos de privacidad y velocidad, dos factores valorados por el usuario final.
El enfoque de Liquid AI ejemplifica cómo la innovación técnica puede repercutir en posicionamiento web: cada nueva arquitectura abre búsquedas, debates y enlaces desde comunidades de desarrolladores, impulsando la autoridad temática de los medios que explican estas tecnologías con detalle.
En definitiva, LFM2.5-230M marca una evolución hacia modelos más compactos, prácticos y energéticamente eficientes. Su adopción podría acelerar la llegada de asistentes y sistemas inteligentes verdaderamente autónomos, integrados en el hardware cotidiano y con un equilibrio inédito entre rendimiento y tamaño.
Preguntas frecuentes
¿Qué es el modelo LFM2.5-230M de Liquid AI?
Es un modelo de inteligencia artificial de 230 millones de parámetros diseñado para ejecutarse directamente en dispositivos locales como teléfonos o robots, sin conexión a la nube.
¿En qué se diferencia LFM2.5-230M de otros modelos más grandes?
A pesar de su tamaño reducido, logra competir en tareas de instrucciones y extracción de datos gracias a la destilación desde modelos mayores, manteniendo eficiencia y bajo consumo.
¿En qué plataformas puede ejecutarse LFM2.5-230M?
Funciona en hardware como Galaxy S25 Ultra, Raspberry Pi 5 y módulos NVIDIA Jetson, y es compatible con frameworks como llama.cpp, vLLM, SGLang y ONNX.
Más noticias de este autor


Seguimiento del tema
Esta cobertura puede ampliarse con nuevas fuentes, consultas de búsqueda y artículos relacionados dentro del mismo eje editorial.