La Carrera por Comprimir el Caché KV: TurboQuant, OSCAR y EpiCache
Exploramos cómo TurboQuant, OSCAR y EpiCache abordan el desafío de la compresión del caché KV en modelos de lenguaje de gran contexto.
Cada nueva herramienta de inteligencia artificial abre oportunidades, pero también plantea preguntas sobre calidad, criterio humano y uso responsable.
Los modelos de lenguaje de gran contexto enfrentan un desafío significativo relacionado con la memoria: el caché de claves y valores (KV) puede superar el peso de los propios modelos. En este contexto, TurboQuant, OSCAR y EpiCache emergen como soluciones innovadoras para abordar esta limitación.
En el mundo de los modelos de lenguaje de gran contexto, la gestión eficiente de la memoria es crucial. A medida que los modelos procesan secuencias largas, el caché de claves y valores (KV) se convierte en una carga significativa que puede superar incluso el peso de los modelos en sí. Este desafío ha impulsado el desarrollo de soluciones como TurboQuant, OSCAR y EpiCache, cada una con su enfoque único para optimizar el uso de la memoria.
Para ampliar el contexto, también puede leerse Check Point e Illumio refuerzan la defensa Zero Trust frente a ciberataques.
Para ampliar el contexto, también puede leerse El legado de una frase paterna que inspira perseverancia.
Para ampliar el contexto, también puede leerse El desafío del agotamiento digital en la era del desarrollo automatizado.
Para ampliar el contexto, también puede leerse Qué es el Query Fan-Out y cómo redefine la visibilidad en buscadores.
TurboQuant: Optimización Teórica y Generalidad
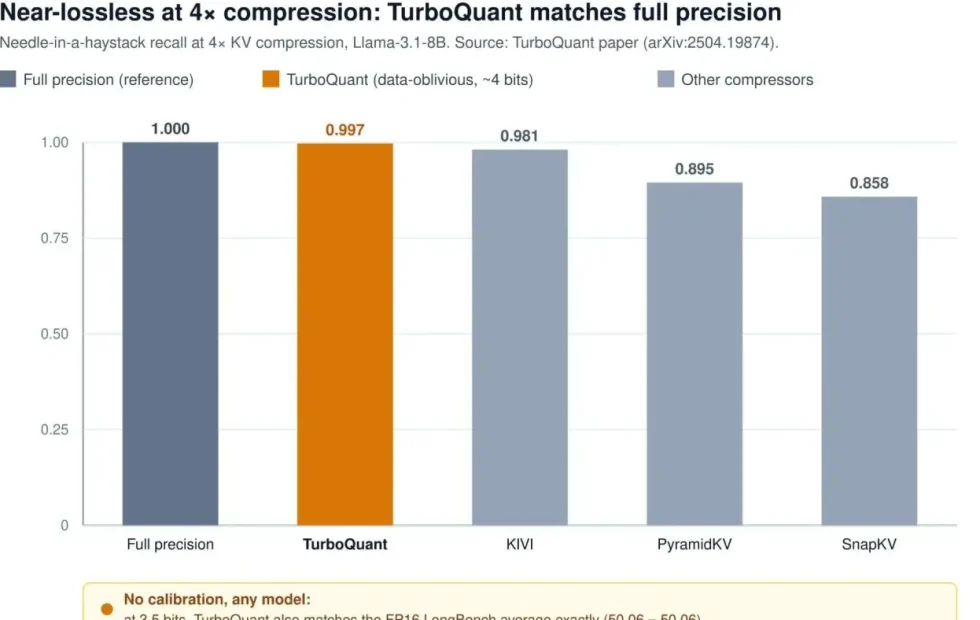
TurboQuant se destaca por su enfoque teórico en la compresión del caché KV. Este método no requiere calibración previa y se adapta a cualquier modelo, ofreciendo compresión casi sin pérdidas en el rango de 3 a 4 bits. Su técnica se basa en una rotación aleatoria de vectores que permite aplicar un cuantizador escalar precomputado de manera óptima. Además, utiliza una transformada de Johnson–Lindenstrauss cuantizada de 1 bit para estimar los logits de atención sin sobrecarga de normalización.
Para profundizar el contexto, también se puede leer: NVIDIA lanza Nemotron 3.5 ASR: Transcripción en tiempo real en 40 idiomas.
OSCAR: Listo para Despliegue y Consciente de la Atención
Por otro lado, OSCAR adopta un enfoque consciente de la atención, utilizando una rotación basada en la covarianza de las consultas y los valores. Este método se integra en un sistema completo que incluye un caché paginado de precisión mixta y kernels Triton fusionados, lo que facilita su implementación en entornos de producción. OSCAR ha demostrado una reducción significativa de la memoria del caché KV y un aumento en el rendimiento de los trabajos.
EpiCache: Gestión de Memoria en Conversaciones Extendidas
EpiCache aborda un problema diferente al centrarse en la gestión de memoria en conversaciones extendidas. Este marco organiza el historial en bloques y utiliza clustering episódico para segmentar las conversaciones en episodios semánticos coherentes. EpiCache ha mostrado mejoras significativas en precisión y reducción de memoria al combinarse con otros métodos de cuantización como TurboQuant u OSCAR.
Por qué esta noticia es relevante
La importancia de estas innovaciones radica en su capacidad para mejorar la eficiencia de los modelos de lenguaje de gran contexto, una necesidad creciente en aplicaciones que requieren procesamiento de grandes volúmenes de datos. Al reducir la memoria necesaria para el caché KV, se disminuyen los costos y se mejora la latencia de decodificación, lo que es crucial para mantener la competitividad en el campo de la inteligencia artificial.
Cómo encaja dentro de la evolución del sector
La evolución de los modelos de lenguaje ha estado marcada por un aumento en la complejidad y el tamaño de los datos procesados. Las soluciones de compresión del caché KV como TurboQuant, OSCAR y EpiCache representan un paso adelante en la gestión eficiente de recursos, permitiendo a los desarrolladores manejar modelos más grandes sin comprometer el rendimiento.
Qué puede ocurrir a partir de ahora
Con la continua expansión de las aplicaciones de inteligencia artificial, es probable que veamos una mayor integración de estas tecnologías de compresión en diversas plataformas. Además, la colaboración entre diferentes enfoques, como la combinación de técnicas de rotación y cuantización, podría dar lugar a soluciones aún más eficientes en el futuro.
Qué oportunidades genera el cambio
Una cobertura responsable sobre inteligencia artificial debería diferenciar hechos confirmados, escenarios posibles, riesgos y criterios de uso antes de recomendar adopción.
Impacto específico para usuarios y empresas
La lectura útil aparece cuando el tema se conecta con una aplicación concreta y no con una promesa genérica de automatización.
Casos de uso que empiezan a aparecer
El valor de esta tendencia dependerá menos del entusiasmo inicial y más de su capacidad para resolver necesidades concretas con seguridad, utilidad y control humano.
Impacto específico de compresión de caché KV
La relevancia de esta novedad no se mide por mencionar inteligencia artificial, sino por explicar qué cambia en el caso concreto: quién puede usarlo, qué problema intenta resolver y qué límites conviene considerar antes de convertirlo en una recomendación.
En torno a La Carrera por Comprimir el Caché KV: TurboQuant, OSCAR y EpiCache, el análisis debe concentrarse en la experiencia real de usuarios, equipos o empresas alcanzadas por el tema. Esa mirada evita transformar cualquier noticia de IA en una lectura genérica sobre automatización.
Aplicaciones concretas y puntos que requieren seguimiento
Para evaluar el alcance de compresión de caché KV, conviene observar si existen usos prácticos, ejemplos verificables, documentación disponible o señales de adopción. Si la información todavía es limitada, la cobertura debe separar hechos confirmados de interpretaciones posibles.
- Identificar qué necesidad específica intenta resolver.
- Revisar si el beneficio es para usuarios finales, empresas o equipos técnicos.
- Observar riesgos de privacidad, dependencia o calidad de resultado cuando correspondan.
- Actualizar la nota si aparecen casos reales, fuentes oficiales o nuevos datos.
Qué puede cambiar para el lector
El valor editorial aparece cuando el lector entiende si esta tendencia puede modificar una decisión concreta: adoptar una herramienta, revisar una estrategia, cambiar un flujo de trabajo o simplemente seguir el tema con más contexto. La cobertura debe ayudar a decidir, no solo sumar volumen de texto.
Preguntas frecuentes
¿Qué es el caché KV en modelos de lenguaje?
El caché KV almacena vectores de claves y valores durante la decodificación para evitar recalcular la atención en cada token, lo que puede ser muy costoso en términos de memoria.
¿Cómo mejora TurboQuant la compresión del caché KV?
TurboQuant utiliza rotaciones aleatorias y transformadas cuantizadas para lograr una compresión casi sin pérdidas, optimizando el uso de la memoria sin necesidad de calibración previa.
¿Qué ventajas ofrece OSCAR para la implementación en producción?
OSCAR proporciona un sistema completo que incluye un caché paginado de precisión mixta y kernels fusionados, facilitando su uso en entornos de producción con mejoras significativas en el rendimiento.
Más noticias de este autor



Seguimiento del tema
Esta cobertura puede ampliarse con nuevas fuentes, consultas de búsqueda y artículos relacionados dentro del mismo eje editorial.